
RAL这个期刊质量是很高的,最近看到了一篇RAL新收录的多传感器融合方向的论文,论文效果不错,因此做一个阅读笔记。
《Unified Multi-Modal Landmark Tracking for Tightly Coupled Lidar-Visual-Inertial Odometry》(RAL2021)
Motivation
就目前而言,多传感器融合方向,相机+视觉+IMU仍然处在松耦合融合的层面,基于增量平滑的紧耦合方法目前仍然有待研究,并且可以预见的是会有比较好的效果,通常来讲,在多传感器融合方向,主要是解决两个问题,如何在计算量有限的平台下实现一个鲁邦性能和如何同步多个传感器不同的频率,这两个问题目前在已有的松耦合融合方法里已经得到了比较好的解决。因此,作者想到了解决实验中遇到的两个问题: 1.如何提取和跟踪稀疏轻量级的特征; 2.如何开发一个相关因子图,可以利用IMU预积分动态的将点云投影到附近相机帧的时间戳。(第一点的motivation可以避免匹配整个点云或者跟踪上百个特征点,第二点的motivation可以尽可能的平滑多传感器的影响)
Contribution
- 提出了一种新的因子图公式,在一个一致的优化过程中紧密地融合了视觉、激光雷达和IMU测量。
- 提出了一种有效的提取激光雷达特征的方法,然后将其优化为地标。激光雷达和视觉特征都有一个统一的表示,因为标志物都被视为n维参数流形(即点、线和平面)。这种紧凑的表示允许我们以标称帧速率处理所有激光雷达扫描。
- 在一系列场景中进行的广泛实验评估表明,与单个传感器模式的方法相比,该方法具有更高的鲁棒性。
Content
-
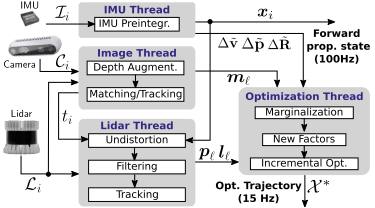
系统框图
如下图,多传感器的输入进行并行处理,后端输出一个高频的传播位姿输出和低频的优化位姿输出。
-
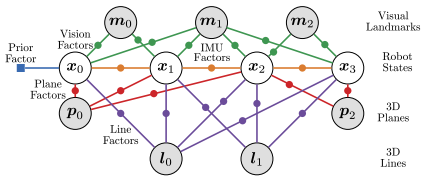
因子图
如下图,因子图里主要包括3种因子,先验因子(IMU),视觉因子(单目和双目),雷达特征因子(线特征和面特征),下面进行一一解读
1).IMU预积分因子
当前的IMU预积分理论已经模块化,具体的公式推导可以阅读《On-manifold preintegration for real-time visual-inertial odometry》(TOR2017), 这里就直接给出文章中对于IMU问题参数的定义: \(r_{I_{i,j}}=[r^T_{\delta_{R_{i,j}}},r^T_{\delta_{v_{i,j}}},r^T_{\delta_{P_{i,j}}},r_{b^a_{i,j}},r_{b^g_{i,j}}]\)
2)单目视觉特征因子
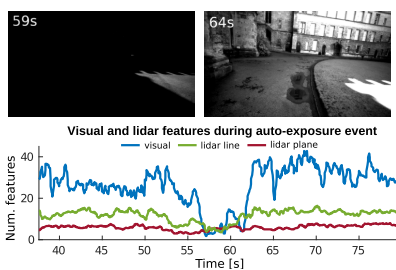
这里说的单目视觉特征因子主要指的是经过雷达深度图获取深度的单目重投影误差,具体操作如下图:黄点是视觉FAST特征点,红线是雷达特征线,绿面是雷达特征面,在获取雷达数据后,将雷达点投影到右侧的相机图像上,对于相机特征点和雷达点的距离小于一定阈值的,进行深度关联操作.
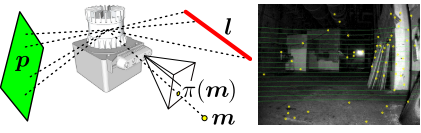
因此,这个因子的残差计算如下:
\[r_{x_{i},m_{l}}=T^{-1}_{i}m_{l}-\hat{X}_{l}\]3)双目视觉特征因子
这个主要是防止出现深度图无法和视觉特征关联情况的出现,实质上就是直接采用了双目的重投影误差:
\[r_{x_{i},m_{l}}=\begin{pmatrix} \pi^L_{u}(T_i,m_l)-u^L_{i,l}\\ \pi^R_u(T_i,m_l)-u^R_{i,l}\\ \pi_v(T_i,m_l)-v_{i,l} \end{pmatrix}\]4)雷达平面因子
使用海塞法向量来参数化一个不定平面,然后再用一个标量来表示到原点的距离,用$\ominus $表示两个平面的误差,用$\otimes$表示对平面施加一个位姿变换 \(p=\{<\hat{n},d>\in R^4\ |\ \hat{n}*(x,y,z)+d=0\}\\ p_{i}\ominus p_{j}=(B^T_{p}\hat{\varepsilon },d_{i}-d_{j})\in R^3\\ \hat{\varepsilon }=-\frac{arccos(\hat{n}_{i}*\hat{n}_{j})}{1-(\hat{n}_{i}*\hat{n}_{j})^2}(\hat{n}_j-(\hat{n}_i*\hat{n}_j)\hat{n}_i)\in R^3\\ \\ predict=(T^{-1}_i\otimes p_{l})\ominus \hat{p}_{i}\)
5)雷达线因子
使用一个旋转矩阵R和两个标量来参数化一个不定平面:
线的方向表示:$\hat{v}=R\hat{z}$
线上离原点最近点的表示:$d=R(a\hat{x}+b\hat{y})$
因此,最终线可以表示为:
\[l=\{<R,(a,b)>\in SO(3)\times R^2\}\]用$\otimes$表示对一个直线施加一个位姿变换,那么经过变换后的直线的参数表示如下:
\[R_j=R_{ij}R_i\\ a_{j}=a_i-[1\ 0\ 0]R^T_{i,j}p_{ij}\\ b_j=b_i-[0\ 1\ 0]R^T_{i,j}p_{i,j}\]然后用$\ominus$表示两个直线之间的误差:
\(l_i\ominus l_j=(\begin{bmatrix} 1&0 \\ 0&1 \\ 0&0 \end{bmatrix}^T Log(R^T_iR_j),a_i-a_j,b_i-b_j)\in R^4\) 传播预测的直线如下: \(r_{x_{i},l_{f}}=(T^{-1}_{i}\otimes l_{f})\ominus\hat{l_i}\)
-
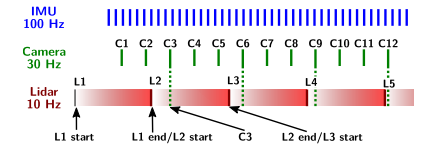
去畸变和传感器时间同步
其实就是利用线性插值,将点云去畸变到最近的相机时间戳,如下图:
-
雷达线和雷达面跟踪的阈值设置
面:法向量夹角小于一定的阈值,对于原点的距离小于一定的阈值 \(\delta_n=\|arccos(\hat{n}_i*\hat{n}_j)\|\le \alpha_p\\ \delta_d=\|\hat{n}_id_i-\hat{n}_jd_j\|\le \beta_p\) 线:向量夹角小于一定的阈值,对于原点的距离小于一定的阈值
\(\delta_n=\|arccos(\hat{v}_i*\hat{v}_j)\|\le \alpha_l\\ \delta_d=\|(d_i-d_j)-((d_i-d_j)*\hat{v}_i)\hat{v}_i\|\le\beta_l\) 论文中给出的经验值为: $\alpha_p=\alpha_l=0.35rad,\beta_p=\beta_l=0.5m$
5.实验结果
1).城市中,人剧烈走动数据集(NC数据集,2020发布)

2).地下数据集(作者自己采集)
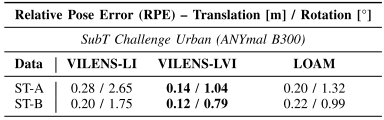
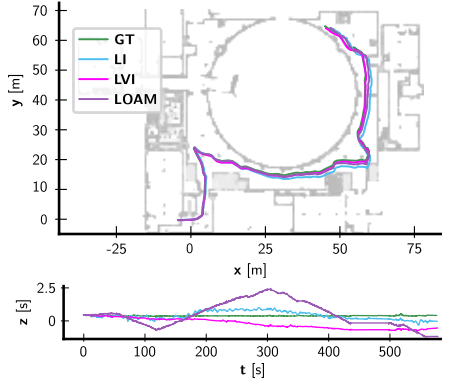
3).可视化分析
可视化分析主要分析的是轨迹,主要是体现出多传感器融合的时候,在有一部分传感器失灵情况下,里程计仍然可以获得比较好的效果。
Content
这篇文章最主要的创新点是用因子图的方式将IMU,lidar,vision进行紧耦合,和VLOAM比较,VLOAM是用VIO作为运动先验,然后高频的VIO作为优化的初始值送给LOAM,所以这个方法的全局稳定性会比较弱,因为事实上的VIO的信息和lidar的信息没有进行强关联.所以后续zhangji的学生wang就基于这个问题在vloam的基础上加上后端的全局位姿图优化来提升全局持续性(19年IROS)。紧耦合视觉+激光的目前主要有LIMO,VIL,LIC1&2,limo紧耦合主要体现在视觉前段特征点和激光雷达深度的关联,VIL融合的方式主要是独立进行激光视觉各自的独立里程计然后滤波融合, LIC1.0主要是利用雷达的线特征与视觉特征进行融合,LIC2.0主要是在LIC1.0的基础上加了一个滑窗机制。
总的来说,这篇文章提出的基于因子图优化的激光视觉紧耦合方法确实是比较新颖的,并且实验结果也得到了验证,值得一读。